- In the fast-evolving digital landscape, mastering the art of scalability and implementing robust failover strategies is crucial for ensuring your applications can handle increasing demands without compromising performance or reliability.
- In this comprehensive guide, we will explore advanced scalability strategies, delve into the intricacies of failover servers, and provide real-world examples to illustrate how these techniques are successfully applied.

Single-Server Design 🏢
- Single-Server Design, also known as a monolithic architecture, is a system architecture in which all the components of an application, including the user interface, application logic, and database, are tightly integrated and run on a single server or machine.
- In this design, a single server is responsible for handling all aspects of an application's functionality.

Components of Single-Server Design:
- The user interface (UI) of the application, which includes the frontend, is typically hosted on the same server. This is where users interact with the application, and it handles user requests and displays content.
- The application logic, responsible for processing user requests, managing data, and performing business operations, is also part of the single server. It includes the code that makes the application function.
- The database, where application data is stored and retrieved, is often colocated with the UI and application logic. This means that the server runs the database management system (DBMS) and stores all the data locally.
Technical Aspects of Single-Server Design:
- One of the key advantages of a single-server design is its simplicity. It's easy to set up and maintain because all components are in one place. This can be beneficial for small-scale applications with minimal traffic.
- Hosting everything on a single server can be cost-effective, especially for small businesses or startups with limited resources. There's no need to invest in complex infrastructure.
- For applications with low to moderate traffic, a single server can provide acceptable performance. It might handle everyday tasks effectively without the need for elaborate architecture.
- Simplicity🎈: The simplicity of a single-server design makes it easy to set up and maintain, particularly for small projects with straightforward requirements.
- Cost-Effective💸: It's a cost-effective solution, ideal for projects with limited budgets.
- Limited Scalability 🛑: The most significant drawback of a single-server design is its limited scalability. As user traffic increases, the server can quickly become a bottleneck, leading to performance issues and downtime.
- High Risk ☠️: Since all components are on a single server, if that server fails, the entire application can go down. This poses a high risk in terms of availability and data loss.
Cloud Services Example:
- Utilising services like AWS EC2 or Google Cloud VM instances, you can initially deploy your application on a single virtual server. However, to achieve better scalability, it's essential to consider more advanced strategies. ☁️
Use Cases and Limitations:
- Single-server design is suitable for small projects, personal websites, or applications with low traffic and resource demands. However, it's not appropriate for applications that require high availability, robust scalability, or data redundancy.
- As an application grows and attracts more users, the limitations of a single-server design become evident.
- To address these limitations, businesses often need to transition to more scalable and fault-tolerant architectures, such as those involving load balancing, horizontal scaling, and distributed databases. These architectural changes allow the application to handle increased traffic and maintain high availability. 🚀🏗️
Conclusion:
- As an application grows and attracts more users, the limitations of a single-server design become evident. To address these limitations, businesses often need to transition to more scalable and fault-tolerant architectures, such as those involving load balancing, horizontal scaling, and distributed databases.
- These architectural changes allow the application to handle increased traffic and maintain high availability. 🚀🏗️
Separate Out Databases 🗂️
- Separate Out Databases also known as a split-database architecture, is an approach in system design and architecture where the components responsible for managing the application's data are physically separated from other parts of the application.
- In this setup, the database, which stores, retrieves, and manages the application's data, runs on distinct servers or infrastructure from the application's frontend and backend components.
- Let's delve into the details of this approach.
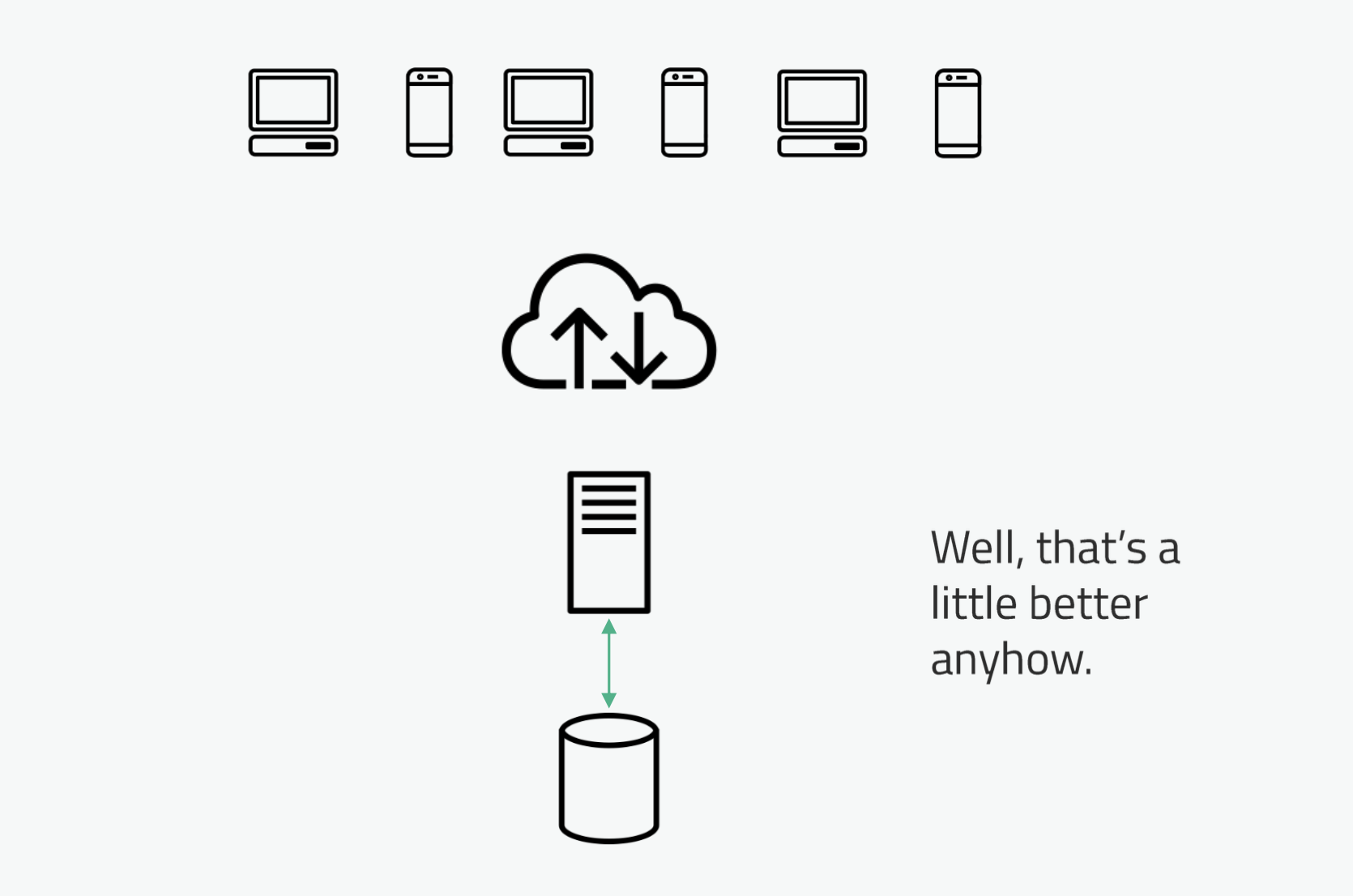
Components of Separate Out Databases:
- Application Servers: These servers or machines host the frontend and backend components of the application. They handle user requests, process business logic, and manage the user interface.
- Database Servers: These servers are dedicated to running the database management system (DBMS) and storing the application's data. They focus solely on data storage and retrieval.
- Physical Separation: The core principle of this architecture is the physical separation of the application's servers and the database servers. They can be located in different data centers or cloud environments.
- Network Connectivity: Application servers communicate with the database servers over a network. This separation allows for optimized resource allocation and efficient data management.
- Database Management: Database servers are responsible for managing data storage, indexing, querying, and ensuring data consistency. This specialization can lead to better data performance and reliability.
- Improved Data Organizatio🗄️: By separating out databases, data can be organized more efficiently. It's easier to manage and maintain data when it's the primary focus of the server.
- Independent Scaling 🔄: Application servers and database servers can be scaled independently based on their respective requirements. This allows for optimized resource allocation and performance tuning.
- Data Security 🔐: Data can be more securely managed when it's isolated on dedicated servers. Access control and security measures can be implemented more effectively.
Disadvantages of Separate Out Databases:
- Complexity 🧩: Managing a split-database architecture can be more complex than a monolithic setup. It requires coordination between application and database components and may introduce additional networking considerations.
- Data Synchronization 🔄: Ensuring that data remains consistent between the application servers and database servers can be a challenge. Synchronization processes need to be in place to maintain data integrity.
Use Cases and Limitations:
- Large Applications: Separate out databases are commonly used in large-scale applications with heavy data processing requirements, such as e-commerce platforms, social media networks, and enterprise resource planning (ERP) systems.
- High-Traffic Websites: Websites with high traffic volumes benefit from this architecture as it allows for the scaling of database resources independently of the frontend, ensuring smooth user experiences.
- Data-Intensive Applications: Applications that heavily rely on data, like analytics platforms or content management systems, can take advantage of the optimized data management provided by this architecture.
- Limitations: While this architecture is effective for many scenarios, it may introduce complexity, and setting up and maintaining the network infrastructure between application and database servers requires careful planning.
Cloud Services Example:
- Cloud-based managed databases like Amazon RDS and Azure Database for PostgreSQL enable effortless separation of your database layer, ensuring efficient data processing and storage. 🗃️
Conclusion:
- Separate Out Databases is an architectural approach that involves physically separating the application's frontend and backend components from the database servers.
- This separation enables improved data organization, independent scaling, and enhanced data security, making it a preferred choice for large, data-intensive applications and high-traffic websites. However, it does introduce complexity and requires careful management of data synchronisation.
Vertical Scaling (Scaling Up)⬆️
- Vertical Scaling, also known as Scaling Up, is a system scalability strategy in which you increase the capacity and performance of a single server or machine by adding more resources, such as CPU cores, memory (RAM), or storage.
- This approach aims to handle increased workloads and improve an application's performance without changing its fundamental architecture.

Key Aspects of Vertical Scaling:
- Resource Expansion 💪: Vertical scaling involves enhancing the capabilities of an existing server by adding more resources, which can include increasing the number of CPU cores, upgrading the CPU to a faster model, adding more RAM, or expanding storage capacity.
- In-Place Upgrades 🛠️: It typically requires making in-place upgrades to the existing server hardware. This means taking the server offline temporarily to perform the upgrades. Depending on the hardware and system, this process can be performed without major application downtime.
- Scalability Limit ⚠️: Vertical scaling has an inherent limit. While you can boost the performance of a server significantly, you're ultimately constrained by the maximum capacity of the hardware. Once this limit is reached, further scaling by adding resources becomes impractical.
- Quick Performance Improvement ⚡: Vertical scaling can lead to a quick and noticeable improvement in performance without the need for significant architectural changes. This can be especially useful for addressing sudden spikes in traffic or resource-intensive tasks.
- Simplified Management 🧐: Since you're working with a single server, management and administration may be simpler compared to complex distributed systems.
- Legacy Application Support 🕰️: Vertical scaling is a viable option for legacy applications that may not be easily adaptable to distributed or horizontally scaled architectures.
Disadvantages of Vertical Scaling:
- Hardware Limitation 🧱: There is a finite limit to how much you can scale vertically. Once you reach the maximum hardware capacity, you'll need to consider other scalability strategies.
- Cost 💰: Acquiring high-end server hardware can be expensive. Moreover, the cost per performance improvement may not be linear, making it less cost-effective for very high workloads.
- Downtime ⏳: Upgrading server hardware can result in temporary downtime, which can impact application availability and user experience.
Use Cases for Vertical Scaling:
- Database Servers 🗃️: Vertical scaling is often used to enhance the performance of database servers. Adding more CPU power or RAM can improve query processing speed and overall database performance.
- Enterprise Applications 🏢: Many enterprise applications, such as customer relationship management (CRM) systems or resource planning tools, benefit from vertical scaling. These applications can experience increased usage over time, and upgrading the server can help maintain optimal performance.
- On-Premises Servers 🏭: Vertical scaling is more common in on-premises data centers where resources are added to existing hardware to accommodate growing workloads.
Cloud Services Example:
- Cloud providers offer resizable instances, allowing you to vertically scale resources based on your application's evolving requirements. AWS EC2 instances and Google Cloud Compute Engine are prime examples. 🖥️
Limitations and Transition to Horizontal Scaling 🔄:
- While vertical scaling can provide a quick and effective performance boost, it's important to recognize its limitations. For applications that continue to grow and require even more scalability, a transition to horizontal scaling (scaling out) may be necessary.
- In horizontal scaling, you add more servers to the infrastructure, distributing the load across multiple machines. This approach is more suitable for handling extremely high workloads and offers improved fault tolerance.
Horizontal Scaling (Scaling Out) 🌐
- Horizontal Scaling, also known as Scaling Out, is a system scalability strategy that involves increasing the capacity and performance of an application by adding more servers or machines to the existing infrastructure.
- Unlike vertical scaling (scaling up), which focuses on enhancing the resources of a single server, horizontal scaling focuses on distributing the workload across multiple servers.
- This approach is often used to accommodate growing workloads, improve fault tolerance, and ensure high availability.

Key Aspects of Horizontal Scaling:
- Adding Servers 🚀: Horizontal scaling involves adding new servers or machines to the existing infrastructure. These servers can be physical machines or virtual instances in a cloud environment.
- Load Distribution 🚴♀️: Load balancers are commonly used in horizontal scaling to evenly distribute incoming user requests and traffic across the available servers. This ensures that no single server becomes overwhelmed and that resources are utilized efficiently.
- Independence 🤝: In horizontal scaling, each server is independent and capable of handling user requests on its own. Servers may run the same application code and share a common database or data storage, but they function as separate entities.
Advantages of Horizontal Scaling:
- Scalability 📈: Horizontal scaling is highly scalable. As the application's demand increases, you can keep adding more servers to the infrastructure, allowing it to handle higher workloads and traffic.
- Fault Tolerance 🛡️: Since multiple servers are involved, horizontal scaling provides built-in fault tolerance. If one server fails, others can continue to serve user requests, ensuring high availability.
- Improved Performance 💨: Distributed load handling leads to improved performance and responsiveness, as user requests are processed in parallel across multiple servers.
- Cost-Efficiency 💰: Adding more servers can be a cost-effective way to scale, especially in cloud environments, as you can provision and de-provision resources as needed.
Disadvantages of Horizontal Scaling:
- Complexity 🧩: Managing a distributed system with multiple servers can be more complex than managing a single server. Configuration, synchronization, and monitoring become critical.
- Data Consistency 🔄: Ensuring data consistency and synchronization across multiple servers can be challenging. Solutions like distributed databases or caching mechanisms may be required.
- High-Traffic Websites 🌐: Horizontal scaling is often used by websites and web applications with unpredictable or variable traffic patterns, such as social media platforms and e-commerce sites.
- Cloud-Based Applications ☁️: Cloud computing platforms, such as AWS, Azure, and Google Cloud, make it easy to implement horizontal scaling by adding or removing virtual instances based on demand.
- Microservices Architectures 📦: Applications built using microservices benefit from horizontal scaling. Each microservice can run on multiple server instances, allowing for flexible resource allocation.
Cloud Services Example:
- Cloud platforms offer auto-scaling solutions and load balancing services. AWS Auto Scaling and Google Cloud Load Balancing automatically manage server instances and distribute traffic, ensuring efficient horizontal scaling. 🚁
Transition to Horizontal Scaling:
- To implement horizontal scaling, the application needs to be designed with scalability in mind. This typically involves breaking down the application into smaller, stateless components that can run independently on multiple servers. These components should be able to share data or state as needed while maintaining data consistency.
Conclusion:
- horizontal scaling (scaling out) is a scalability strategy that involves adding more servers to an infrastructure to distribute workloads and handle increasing traffic.
- It offers advantages such as scalability, fault tolerance, improved performance, and cost-efficiency, but it also introduces complexities related to configuration and data synchronization.
- Horizontal scaling is a crucial strategy for modern applications that require flexibility, high availability, and the ability to accommodate variable workloads. 🌐🚀
Load Balancing 🚀
- Load Balancing is a design and architectural approach used in computer networks and server environments to efficiently distribute incoming network traffic or workload across multiple servers or resources.
- The primary goal of load balancing is to ensure that no single server becomes overwhelmed with traffic, thereby improving the overall performance, responsiveness, and fault tolerance of an application or network.

Key Aspects of Load Balancing:
- Traffic Distribution 🌐: Load balancers evenly distribute incoming requests, such as web page requests, API calls, or database queries, across a group of servers or resources.
- Health Monitoring 🏥: Load balancers continuously monitor the health and status of the servers in the cluster. If a server becomes unresponsive or experiences issues, the load balancer can redirect traffic away from it.
- Scalability 📈: Load balancing is a critical component for scaling applications. As traffic increases, you can add more servers to the pool, and the load balancer will adapt to distribute the load.
- Session Persistence 🔄: Some applications require that a user's requests are consistently sent to the same server for a session. Load balancers can be configured to maintain session persistence when needed.
Load Balancing Algorithms:
- Several algorithms are used by load balancers to determine how traffic is distributed:
- Round Robin 🔵: Requests are distributed in a cyclic order to each server in the pool. It's a simple and fair method but may not consider server load.
- Least Connections 🏢: Traffic is directed to the server with the fewest active connections. This ensures that the server with the least load gets the traffic.
- Weighted Round Robin ⚖️: Servers are assigned weights, and the load balancer distributes traffic based on these weights. Servers with higher weights receive more requests.
- Weighted Least Connections ⚖️: Similar to weighted round robin, but it considers the number of active connections when distributing traffic.
- IP Hash 📛: The load balancer uses a hash of the client's IP address to determine which server should handle the request. This ensures session persistence for the same client.
Advantages of Load Balancing:
- Scalability 📈: Load balancing enables applications to handle increasing traffic and workloads by distributing them across multiple servers.
- High Availability 🛡️: Load balancers can detect server failures and automatically route traffic away from problematic servers, ensuring high availability.
- Improved Performance 💨: By distributing traffic, load balancers prevent any single server from becoming a bottleneck, leading to better performance and responsiveness.
- Efficient Resource Utilization 🔄: Load balancers optimize resource utilization, reducing the need for over-provisioning individual servers.
- Fault Tolerance 🛡️: Load balancing enhances fault tolerance by ensuring that if one server fails, the application remains accessible through other servers.
Disadvantages of Load Balancing:
- Complexity 🧩: Implementing load balancing can add complexity to the network architecture, requiring configuration and maintenance.
- Single Point of Failure ☠️: The load balancer itself can become a single point of failure if not configured for redundancy.
- Session Persistence Challenges 🔄: Maintaining session persistence can be challenging, particularly for stateful applications.
- Web Servers 🌐: Load balancing is commonly used for distributing web traffic across multiple web servers to handle high traffic websites.
- API Servers 📡: Load balancers can evenly distribute requests to API servers, ensuring efficient API performance.
- Database Servers 🗃️: For database clusters, load balancing can be used to distribute read and write requests across multiple database nodes.
- Application Servers 🏢: Enterprise applications often employ load balancing to distribute workloads and achieve high availability.
- Content Delivery 📦: Content delivery networks (CDNs) use load balancing to distribute content efficiently to users.
Cloud Services Example:
- Cloud providers offer managed load balancing services, such as AWS Elastic Load Balancing and Google Cloud Load Balancing, ensuring seamless distribution of traffic and enhanced application reliability. 🔄
Conclusion:
- load balancing is a critical design approach to distribute incoming traffic or workload across multiple servers, improving scalability, performance, and fault tolerance.
- It plays a vital role in ensuring that applications can handle high traffic, provide uninterrupted services, and efficiently utilize server resources.
- Different load balancing algorithms can be chosen based on specific requirements, and proper configuration is essential to achieve the desired results. 🌐🚀
Failover Server Strategies 🚀
- Failover Server Strategies are crucial for ensuring high availability and minimizing downtime in IT systems. They involve the design and implementation of backup servers or resources that automatically take over when the primary server or resource experiences a failure.
- Here are the types of failover server strategies along with cloud services and real-world examples:
Types of Failover Server Strategies:
1. Cold Standby 🧊:
- In a cold standby setup, a secondary server is kept in a powered-off or dormant state until it's needed. When the primary server fails, the secondary server is manually powered on and configured to take over.
- Advantages:It's a cost-effective solution since the secondary server is not actively running. It's suitable for applications where downtime can be tolerated until manual intervention occurs.
- Disadvantages: Activation time is longer, as it requires manual intervention. Data may not be up-to-date if synchronization is infrequent.
- Cloud Services: Cloud providers offer cold standby solutions. For example, Amazon Web Services (AWS) provides Amazon EC2 instances that can be kept in a stopped state until needed, helping to reduce costs.
- Real-World Example: A small e-commerce business uses a cold standby EC2 instance in AWS to save costs. When the primary instance experiences a failure, they manually start the cold standby instance and reconfigure it for their online store.
- Use Cases:
- Small businesses with limited IT budgets.
- Applications where brief downtime is acceptable.

2. Warm Standby ☕:
- A warm standby server is partially active, running essential services and data synchronization processes. It can quickly take over from the primary server when needed.
- Advantages: Faster activation than a cold standby, as some services are already running. It's suitable for applications where minimal downtime is acceptable.
- Disadvantages: It consumes more resources than a cold standby due to the partially active state.
- Cloud Services: Cloud providers like Microsoft Azure offer warm standby options through virtual machines (VMs) and load balancers. Azure Traffic Manager can distribute traffic to the active and warm standby VMs.
- Real-World Example: A healthcare institution maintains warm standby virtual machines in Azure to ensure minimal downtime for their patient records system. When the primary VM experiences issues, the warm standby VM is quickly activated.
- Use Cases:
- Healthcare systems where quick access to patient data is critical.
- E-commerce platforms that require rapid failover.

3. Hot Standby 🔥:
- A hot standby server is fully active and continuously mirrors the primary server's services and data. It's always ready to take over seamlessly in case of a primary server failure.
- Advantages: Near-instant activation, minimal downtime, and data is always up-to-date. It's suitable for critical applications where uninterrupted service is essential.
- Disadvantages: It consumes more resources than cold or warm standbys and can be more expensive to maintain.
- Cloud Services: Cloud providers such as Google Cloud offer hot standby solutions through services like Google Cloud Load Balancing and the ability to set up auto-scaling and redundancy for virtual machines.
- Real-World Example: An online banking platform maintains a hot standby architecture in Google Cloud to ensure 24/7 access to customer accounts. When the primary server experiences any issues, traffic is automatically rerouted to the hot standby, providing seamless service.
- Use Cases:
- Online banking platforms that demand 24/7 access.
- Emergency response and public safety systems.

Use Cases for Failover Server Strategies:
- Mission-Critical Applications: Failover strategies are essential for applications where even brief downtime can result in significant financial losses or safety risks, such as financial trading systems, healthcare applications, or emergency response systems.
- E-commerce: E-commerce platforms rely on failover strategies to ensure that online stores remain operational during high-traffic periods or server failures.
- Data Centers: Data centers often use failover strategies to maintain the availability of hosted services and data storage.
- Cloud Services: Cloud providers offer failover capabilities for their services to enhance reliability.
- High Availability: Failover strategies ensure continuous service availability, reducing the impact of failures.
- Data Integrity: Data is protected and synchronized, minimizing the risk of data loss during a failure.
- Automatic Recovery: Failovers occur automatically, minimizing the need for manual intervention.
Disadvantages of Failover Server Strategies ☠️:
- Complexity: Setting up and maintaining failover systems can be complex and require expertise.
- Cost: The redundancy of hardware and resources can be expensive.
- Resource Utilization: Hot standby systems consume resources even when idle.
Conclusion:
- Failover server strategies are critical for maintaining high availability and minimising downtime in IT systems. By using redundancy, monitoring, and automatic failover processes, organisations can ensure that services remain operational even in the face of hardware or software failures.
- The choice of cold, warm, or hot standby depends on the application's requirements and the acceptable level of downtime. 🔄🔥🛡️☠️


